8086的通用寄存器
ax bx cx dx si di bp sp
每个寄存器由16位。
其中ax-dx 可以分为两个8位的寄存器来用,其中给每个8位的寄存器分为高位H 和低位L。
例如寄存器DH 为08(十六进制) DL为3C(十六进制),那么DX寄存器的值为083C。
intel8086 如何访问内存
16根数据线
数据线的宽度和寄存器的宽度是一样的,都是16位。
当把AX 中的内容写进内存中时,也是分开写的,会被拆分为两个八位,高八位和第八位,存进内存的保存格式也是对应的---称为低端字节序,如果寄存器的高位写进内存的低地址单元,低位写进内存的高地址单元 ---- 称为高端字节序。
例题: 寄存器BX的内容是55AA (十六进制),在将它写入内存时,指定的地址是0008,低端字节序。那么写入后,将占用几个内存单元? 它们的地址分别是多少? 它们的内容是什么 (采用十六进制)?
一个BX 为16位,所以再内存中占用两个内存单元(一个内存单元占一字节)。
地址分别为0008 0009
其中0008 --->AA ; 0009 ---> 55,因为低端字节序的存储到内存中的顺序是按照
寄存器中的高低顺序来的。
程序在内存中式如何分段存放的
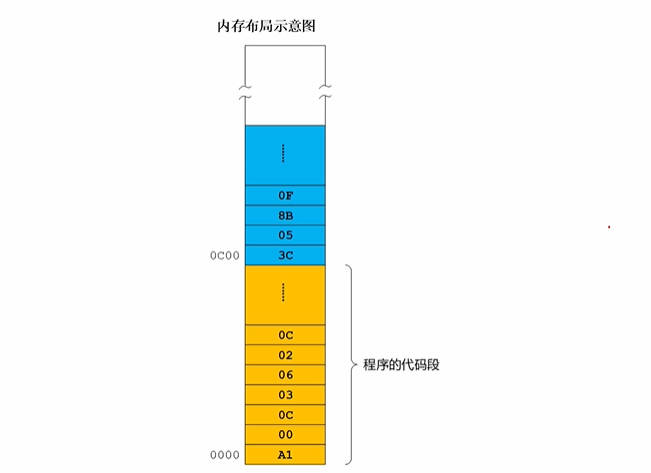
黄色代表代码段,蓝色代表数据段 他们占用的都是连续的区段 图中指令段从0000,’ax 00 0c’ 代表将内存地址0c00处的一个字传送到AX寄存器中。 #此时寄存器ax=053c ‘03 0c 02 0c’ 代表将寄存器ax的内容和内存0c02处的字相加,结果存放到ax中。 #此时ax寄存器中的内容为
```python
hex(int('053c',16) + int('0f8b',16))[2:] #结果为14c7
```
程序的重定位问题
其中有一个寄存器叫做 IPR,它存放了下一条指令的地址:
用当前指令的地址,加上当前指令的长度 <img src='https://vbnmjj.github.io/img/汇编/2.jpg' >
如果把程序在内存中的位置整体上移1000个内存单元,第一条指令从1000开始。
ipr被赋值为1000,然后开始执行程序,如果还是执行指令a1 00 0c,就会发现从00 0c内存地址位置取值出错。原因就是使用了物理地址 或者说是绝对地址。
看数据段的053c ,它距数据段起始位置的偏移量式0,说为偏移地址
为0000
看数据段的0f8b ,它距数据段起始位置的偏移量式2,说为偏移地址
为0002
程序改为如下图
 可以看到代码段操作数据的地址写为了偏移地址, 为了配合这种改变,cpu中添加了
dsr寄存器—数据段寄存器。这里传送给dsr的值为1c00,ipr的值为1000。然后取内存
中的地址就是把dsr中的值和偏移地址相加。
显然,经过ipr和dsr这两个寄存器的增加之后,程序放到任意地方都可以执行啦
这样就解决了内存访问的困境。
可以看到代码段操作数据的地址写为了偏移地址, 为了配合这种改变,cpu中添加了
dsr寄存器—数据段寄存器。这里传送给dsr的值为1c00,ipr的值为1000。然后取内存
中的地址就是把dsr中的值和偏移地址相加。
显然,经过ipr和dsr这两个寄存器的增加之后,程序放到任意地方都可以执行啦
这样就解决了内存访问的困境。
2^10 = 1024 相当于10根地址线最多可以访问的地址段。 inte8086 有16根数据线 20根地址线
段寄存器ds 和cs —选择段地址测策略
ds 数据段寄存器 cs 代码段寄存器 分别保存数据段和代码段的起始地址。 他们都是16位的。
看到这里新生疑惑,两个短地址都只有16位,而地址线传送过来的数据是20位, 难道是直接舍弃首段或者是末尾的四位嘛?
答案并不是,而是由于2进制转化为10进制有一个特别有意思的现象就是如果后四位是0000,那么转化为10进制就是直接向后移动4为把0移除即可。 <img src='https://vbnmjj.github.io/img/汇编/4.jpg' >
由于这个特性,可以看出并不是所有内存地址都可以当作短地址,只有以十六进制0结尾的地址才可以当作段地址。
8086的内存访问过程
指令指针寄存器:IP #自动保存下一条指令的偏移地址,同样是16位。
 30ce0 右移四位,给cs ,cs:30ce
33ce0 右移四位,给ds ,ds:33ce
30ce0 右移四位,给cs ,cs:30ce
33ce0 右移四位,给ds ,ds:33ce
第一条指令的偏移地址ip:0000 执行第一条指令: 通过地址线赋值为30ce0 + ip = 30ce0,访问执行第一条指令”A1 00 00”,将偏移地址0000处的字传送到ax寄存器中: 此时执行ds 向高位偏移4位得到33ce0 再和指令中的偏移地址0000 相加得到33ce0。 取出33ce0 中的 “05 3c”放到AX寄存器中。 此时ax = 05sc
指令指针寄存器ip = ip + 3 = 0003 #3是指令长度 执行第二条指令: 访问30ce0 + 0003 = 30ce3 ,取出指令”03 06 00 02” #ADD AX, [0002]